In this long-form tutorial, I’m going to show you an example how you can too use web scraping to gain insights from public web data. I’m gonna be using Scrapy the web scraping framework to scrape football stats from the web. Then I will process the scraped data. Finally, making it really useful for everyone. I will create some basic, simple analysis with matplotlib and pandas. Let’s jump right into it!
This is going to be comprehensive project showcasing how you can make raw soccer data useful and interesting using Scrapy, SQL and Matplotlib. It’s supposed to be just an example because there are so many types of data out there and there are so many ways to analyze them and it really comes down to what is the best for you and your use case.
Scraping and analyzing soccer data Link to heading
Briefly, this is the process I’m going to be using now to create this example project:
-
Write requirements
Figuring out what is really needed to be done. What are our (business) goals and what reports should we create? What would a proper end result look like? What questions do we have? Only after answering these, we can start implementing the project.
-
Identify data fields and source
Planning ahead what data fields and attributes we’ll need to satisfy the requirements. Also, looking for websites where I can get data from.
-
Extract data
Creating scrapers for the website(s) that we’ve chosen in the previous task.
-
Process data
Cleaning, standardizing, normalizing, structuring and storing data into a database.
-
Analyze data
Creating reports that help you make decisions or help you understand data more.
-
Conclusions
Draw conclusions based on analysis. Understand the data.
Write requirements Link to heading
As I said we’re gonna analyze soccer data. I think though “soccer data” is too big of a scope for us right now so let’s say we wanna analyze only goals and match results. We consider matches that has been played in the latest soccer season (2016-17). Regarding soccer leagues, it really depends on how good of a data source we can find. If we could find a website with roughly all the European soccer leagues not just the major ones(Italy, England, Germany, Spain, etc..) that would be the best.
What kind of reports to produce? Link to heading
This is a key question and must be answered before moving on. We have to know what kind of reports we’re gonna create to know exactly what to scrape. So let’s figure it out!
We’re focusing on goals and results. It would be interesting to see some basic overall reports like:
- Average amount of goals
- Average amount of 1st half/2nd half goals
- Amount of home wins/away wins/draws
- The biggest goal difference between two teams
- The biggest comeback in the 2nd half
- Distribution of average goals along the season
So these are just some adhoc ideas. We could think about other thousands of ways to analyze football data. We’re gonna scrape data only to be able to produce these reports. Again, without knowing what exactly you want to have as an end result it’s just a waste of time to write the scraper. This task is done. Let’s move on to Task One.
Identify data fields and source Link to heading
We want to find a website which has all the data fields we need. What are our data fields? We can figure them out having a close look at the report requirements we just wrote. Data fields are data points and they will be scraped by our future scraper. Putting the data fields together we’ll get a Scrapy item or a record in the database.
Going through the report requirements we will need at least these fields:
- Home goals 1st half
- Home goals 2nd half
- Away goals 1st half
- Away goals 2nd half
- Match date
- League
- Country
Scraping only these fields will be enough to generate some interesting reports about soccer matches in the latest season.
Looking for a data source Link to heading
We are getting closer and closer to be able to start writing our scraper. The next step is to find the source of our raw data aka a website we can scrape. So let’s do a research!
I simply start off googling soccer stats.
There are a bunch of website providing soccer stats. We should keep in mind that we’re NOT looking for the fanciest and most modern website. Usually google shows the best sites on its first page for the given keywords but now we are searching for not the best one but the one which just has the data we need and is simple. Simple means now, that the HTML of the site is nicely structured and relatively clean. Also, if we visit the page with JavaScript disabled it’s still displaying the data fields we need. Because we don’t wanna do unnecessary JS handling in our scraper. Our goal now is to find a website which has got all the data preferably on one page or few pages. We are focusing on getting our data as simply and fast as possible.
After about 20-25 minutes of research in google, I found a website that meets the mentioned criterias fully: http://www.stat-football.com/en/
Next, have a look at robots.txt of the website. This file contains information about how our scraper or bot should behave on the site. It usually defines rules like disallowing some bots to visit specific pages or defines the minimum delay between two requests. To be ethical we have to follow the rules defined here. So check our chosen website’s robots.txt (it should be located at the root directory of the server):
User-agent: *
Disallow: /pismo.php
Disallow: /poisk.php
Disallow: /rassylki.php
Disallow: /en/pismo.php
Disallow: /en/poisk.php
Disallow: /pda/pismo.php
Disallow: /pda/rassylki.php
Disallow: /___x/
Disallow: /awstats/
Disallow: /webalizer/
It mentions a few pages that should be avoided. I’m okay with that we don’t wanna mess with those pages anyway.
This kind of website is the perfect website to scrape. Consistent html, relatively fast to scrape through the pages. No Terms Of Use that explicitly prohibit web scraping on the site. Robots.txt is fine. No javascript/AJAX in the background. Nothing. That’s what I like to see!
As a side note, in a real world project you rarely get to choose which website to scrape because you will have probably no choice. Now we got lucky to find a website which is easy to scrape.
So until now, we made a clear picture what we really want to get as an outcome. Then we found a great site to scrape though it took a little time to find it but it was worth effort. We can move forward and design our Scrapy spider. Finally!
Extract data Link to heading
This is what we’re gonna be doing in this task:
- Setting up Scrapy
- Plan the path of our scraper
- Inspecting the website
- Playing around with selectors in Scrapy Shell
- Writing the spider
- Writing cleaning pipelines
- Exporting, saving to SQL database
- Deploying to Scrapy cloud
Setting Up Scrapy Link to heading
We need to install Scrapy and we’re gonna set it up inside a virtual environment. Making sure that our project is somewhat isolated. Let’s create a project directory and setup a virtual environment:
mkdir soccer
cd soccer
virtualenv env
source env/bin/activate
Before installing Scrapy we have to install its dependencies:
sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-devsudo
Finally, install the latest scrapy:
pip install scrapy
If you have other operating system or any problems installing Scrapy, see the installation docs here.
Now we have Scrapy installed in our environment. Each Scrapy project has the same file structure. We can create a Scrapy project with s_crapy startproject_ command.
scrapy startproject soccer
This way, we created an empty scrapy project, the file structure looks like this:
Inspecting the website Link to heading
This is the part when we plan the path of our scraper. We figure out the path our scraper should follow and recognize the easiest way to get our data fields. As we open the web page make sure JS is disabled in the browser so we can interact with the page the same way scrapy does. This is what we can see right on the home page:
There are a bunch of leagues in the sidebar we definitely don’t wanna copy-paste the URLs of each. Let’s play around on the site a little bit and see how we can get to the page where our data is laid out.
We could open a league page to see what data is there:

On the league page there’s not much data we are interested in. But at the end of the page you can see there are several other pages containing data about the certain league. Let’s try them out and see which page should be the best to fetch data from.
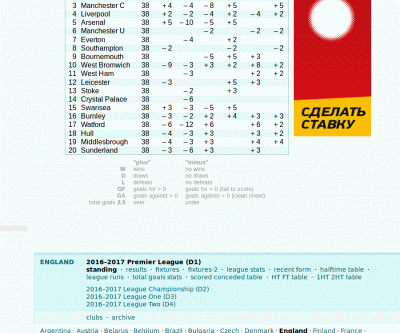
The results page would be great for us but it doesn’t contain data about 1st half/2nd half goals data so it doesn’t fit us now. The fixtures page shows nothing probably because I have JS disabled and it uses JS to load data. Nevermind, the next page fixtures-2 is perfect for us. It contains all the matches that have been played in the latest season also detailed information about goals on each match. All these on one page so we don’t even have to request way too many pages to scrape everything we need.
Until now we figured out which page contains the data we can access the easiest way. The next step is to inspect the html of the pages to write the proper selectors. We’re gonna need multiple selectors:
- League URLs on the sidebar
- Fixtures-2 URL at the bottom of the page
- Data fields in the fixtures table
The first two are for link following purposes. The last one is to fetch actual data.
Playing around with selectors in Scrapy Shell Link to heading
Scrapy shell is an awesome command line tool to test your selectors quickly without running your whole spider. We have to specify a URL and scrapy shell gives us some objects we can work with like response, request etc. So first of all, figure out the selector for league page URLs on the side bar.
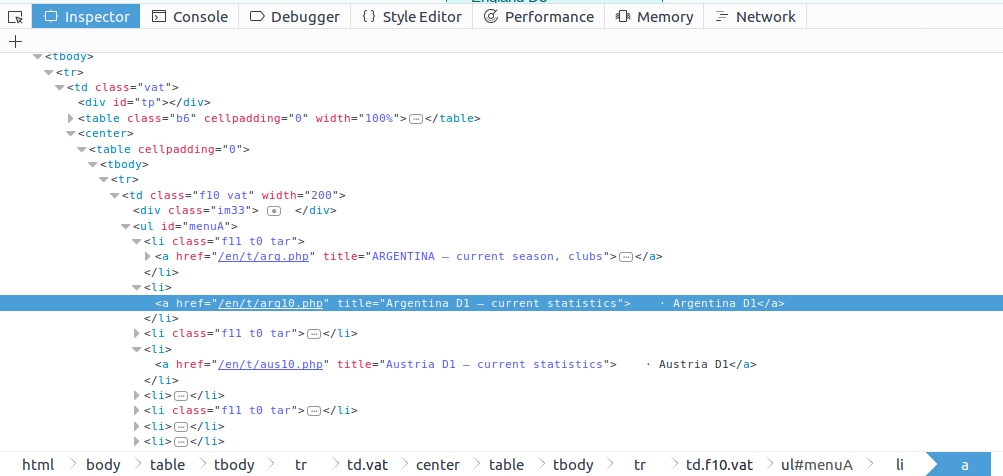
Having a look at the inspector of our browser, we could try “ul#menuA > li” as a selector and see if it selects the proper elements. In order to test it, we have to launch scrapy shell and use the response object:
scrapy shell http://www.stat-football.com/en/
...
In [1]: response.css("ul#menuA > li > a").extract()
Out[1]:
[u'<a href="/en/t/arg.php" title="ARGENTINA u2014 current season, clubs"><b>Argentina</b>xa0 xa0</a>', u'<a href="/en/t/arg10.php" title="Argentina D1 u2014 current statistics">xa0 xa0 xb7 Argentina D1</a>', u'<a href="/en/t/aus.php" title="AUSTRIA u2014 current season, archive, clubs"><b>Austria</b>xa0 xa0</a>', u'<a href="/en/t/aus10.php" title="Austria D1 u2014 current statistics">xa0 xa0 xb7 Austria D1</a>', u'<a href="/en/t/aus20.php" title="Austria D2 u2014 current statistics">xa0 xa0 xb7 Austria D2</a>', u'<a href="/en/t/blr.php" title="BELARUS u2014 current season, archive, clubs"><b>Belarus</b>xa0 xa0</a>', [...]
It selects all the URLs on the sidebar which is not good. We don’t need country URLs we only need URLs for actual soccer leagues. We have to slightly modify the previous selector to exclude the elements we don’t need:
In [2]: response.css("ul#menuA > li:not(.f11.t0.tar) > a").extract()
Out[3]:
[u'<a href="/en/t/arg10.php" title="Argentina D1 u2014 current statistics">xa0 xa0 xb7 Argentina D1</a>', u'<a href="/en/t/aus10.php" title="Austria D1 u2014 current statistics">xa0 xa0 xb7 Austria D1</a>', u'<a href="/en/t/aus20.php" title="Austria D2 u2014 current statistics">xa0 xa0 xb7 Austria D2</a>', u'<a href="/en/t/blr10.php" title="Belarus D1 u2014 current statistics">xa0 xa0 xb7 Belarus D1</a>', u'<a href="/en/t/blr20.php" title="Belarus D2 u2014 current statistics">xa0 xa0 xb7 Belarus D2</a>', u'<a href="/en/t/bel10.php" title="Belgium D1 u2014 current statistics">xa0 xa0 xb7 Belgium D1</a>', u'<a href="/en/t/bra10.php" title="Brazil D1 u2014 current statistics">xa0 xa0 xb7 Brazil D1</a>', [...]
I use the :not css selector to exclude the elements on the sidebar that have “.f11.t0.tar” class which means those are country URLs. So this is the full selector to select league URLs: “ul#menuA > li:not(.f11.t0.tar) > a”. I save it to a text file because we will need it in our spider.
Next, we have to figure out a selector for “fixtures-2” page.
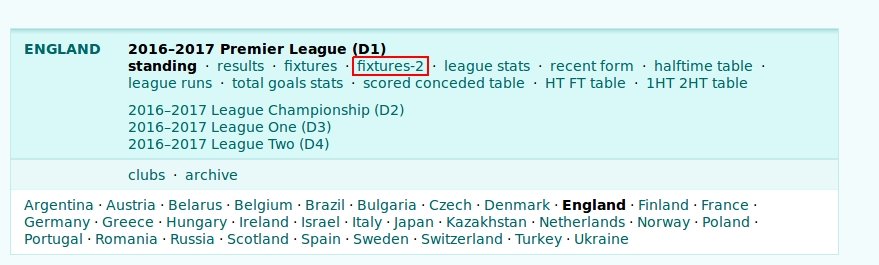
This exactly the element we need let’s see the html.
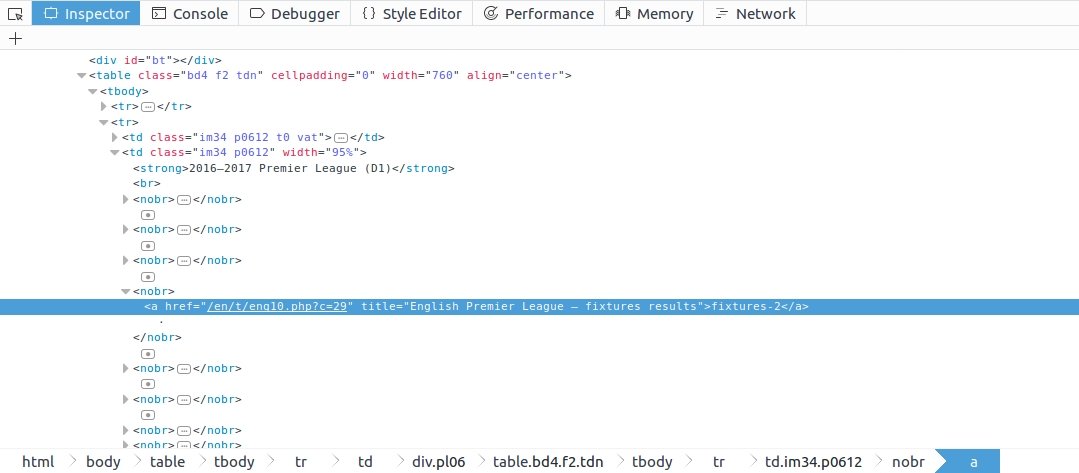
To be honest I have never used or heard before about nobr html tag but that doesn’t matter we can write a selector anyway. As I see, this element we want to select is persistently the 4th nobr element. So let’s try this selector in scrapy shell:
scrapy shell http://www.stat-football.com/en/t/eng10.php
[...]
In [1]: response.css("td.im34.p0612 > nobr:nth-of-type(4)").extract_first()
Out[1]: u'<nobr><a href="/en/t/eng10.php?c=29" title="English Premier League u2014 fixtures results">fixtures-2</a>xa0 xb7xa0</nobr>'
First, it selects the td tag that has got “im34.p0612” class then the 4th nobr tag inside that td. Also, I use extract_first() and not extract() because I want to return only one element not a list of elements like previously. As a side note, when you write selectors based on class and an element has multiple classes then in the selector you have to separate each of them with a dot(.). Like I just did.
Well, we got all the selectors to follow links to our end destination. Now figure out how to select actual data fields we want to scrape. This is an example page our scraper will visit:
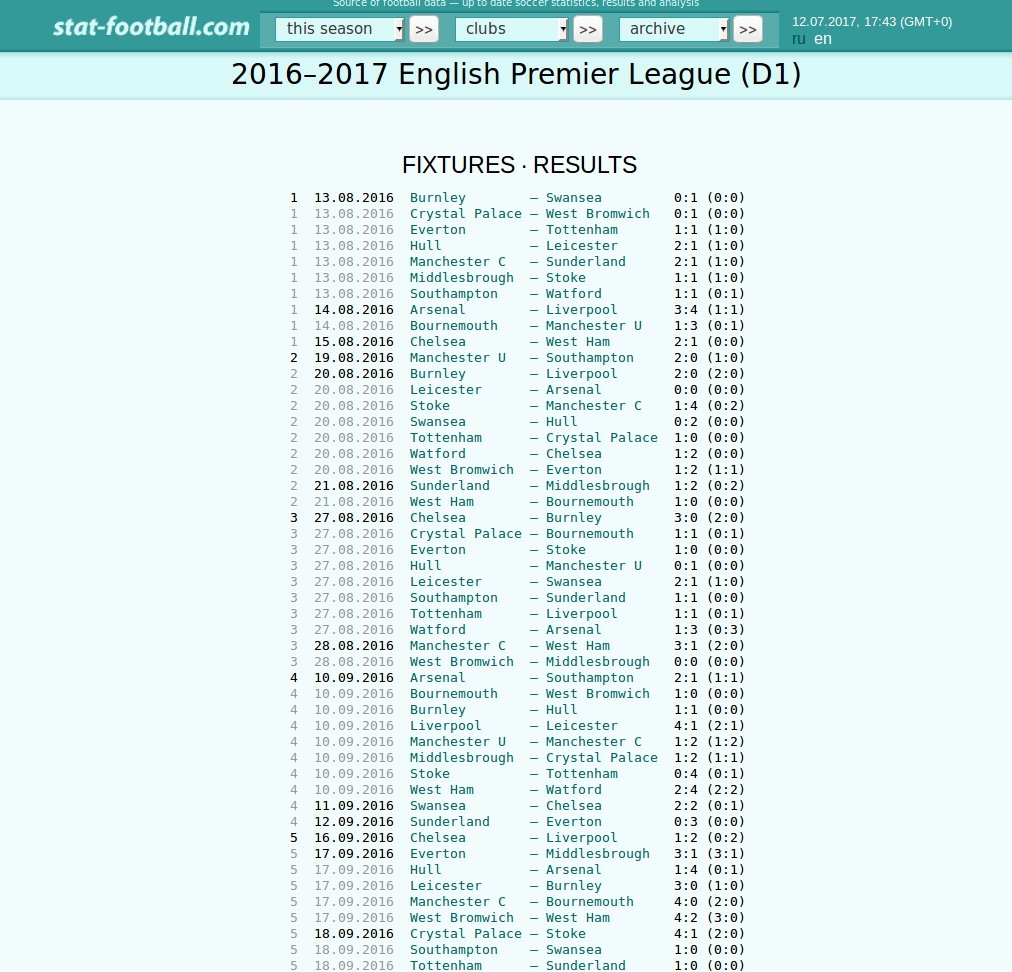
First of all, we are going to write the selectors for the easily selectable fields: league, country. We can select the league field using the title right at the top.
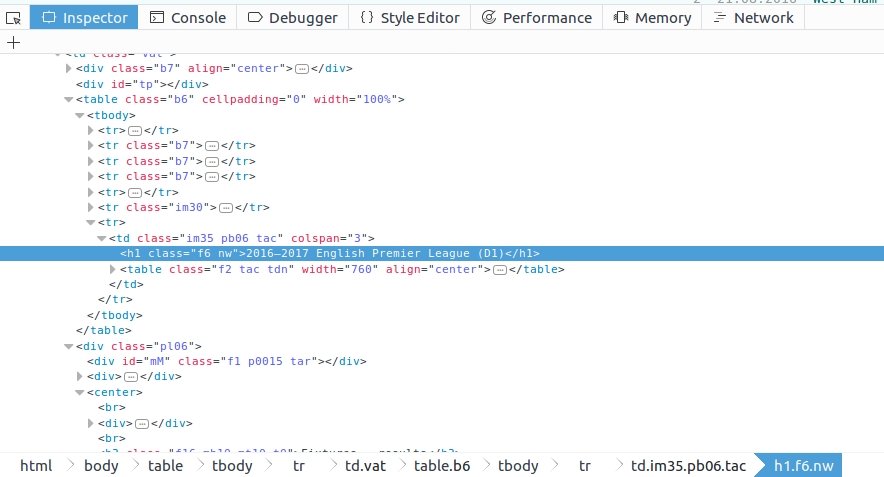
Test in scrapy shell:
scrapy shell http://www.stat-football.com/en/t/eng10.php?c=29
[...]
In [1]: response.css("h1.f6.nw::text").extract_first()
Out[1]: u'2016u20132017 English Premier League (D1)'
It selects the correct title tag. That weird u2013 is just some encoding stuff, the selector works properly.
Now write a selector for the country field. I inspected it a little bit and probably the easiest way to fetch that is at the bottom of the page.
It’s laid out in a separated tag, selector:
In [2]: response.css("td.im34.p0612.t0.vat > a > strong::text").extract_first()
Out[2]: u'England'
Okay, let’s move on to the fields that left: home_team, away_team, home_goals1(first half), home_goals2(second half), away_goals1, away_goals2
At first sight I hoped all the matches are in separate divs or somewhat separated because in that case it should be easy to scrapy each field. I hit up the inspector:
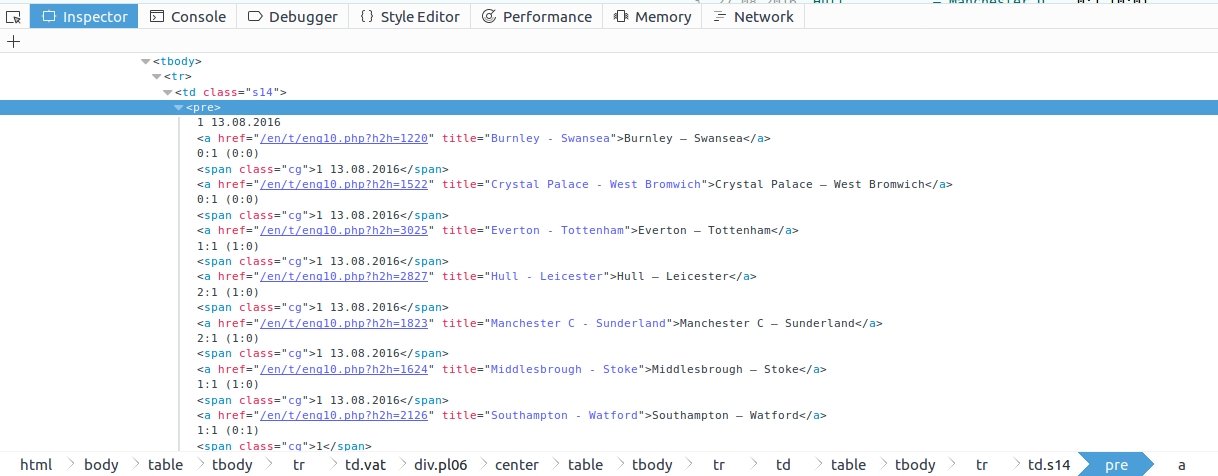
All the stuff is inside one pre tag. Which is not cool. Another problem is that the position of date field is not consistent. Sometimes it’s inside a span sometimes it’s not. Here we need some trickery. Simple selectors like we just wrote is not going to be enough now. A possible solution would be to iterate over each element one-by-one and recognize the item we want to scrape. Let’s hit up scrapy shell once more. Keep in mind, that we want to select all the elements. In order to do that one selector is not enough. We have to write multiple selectors and put them together to select every element of the table, something like this:
scrapy shell http://www.stat-football.com/en/t/eng30.php?c=29
[...]
In [2]: response.css("td.s14 > pre::text, td.s14 > pre > a::text, td.s14 > pre > span::text").extract()
Out[2]:
[u' 1 06.08.2016 ', u'Bolton u2014 Sheffield U ', u' 1:0 (1:0)n', u' 1 06.08.2016 ', u'Bradford u2014 Port Vale ', u' 0:0 (0:0)n', u' 1 06.08.2016 ', u'Bury u2014 Charlton ', u' 2:0 (0:0)n', u' 1 06.08.2016 ', u'Millwall u2014 Oldham ', [...]
This way we have all the elements of the table in a list. Now we just need to figure out a way to recognize when we should populate a new item. Let’s have a look at the table again:
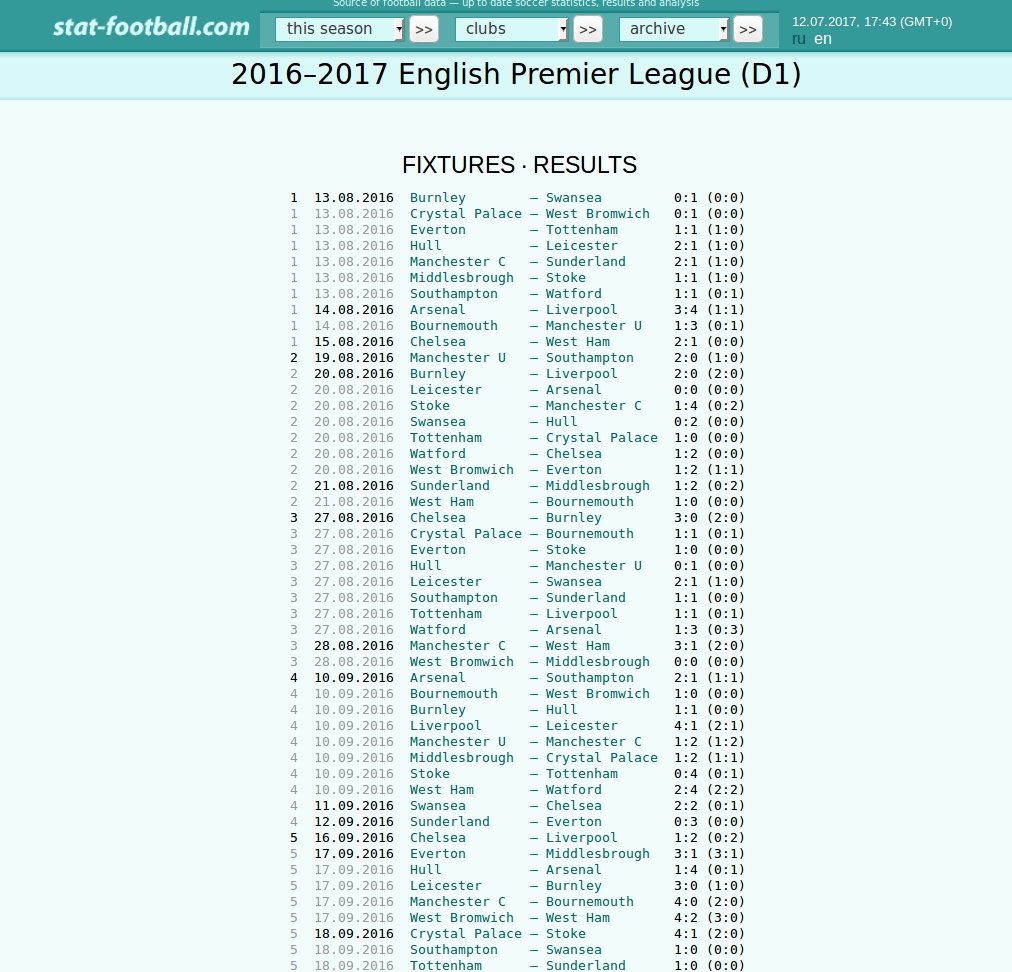
There’s one thing which is sure. Each match has one date. After the date we’ve got the teams and the result in the html structure. So we should iterate over the list of elements and recognize if the element is a date. If it is then it’s time to start populating a new item. This way we will need further data processing because we cannot scrape each field separately. So this is what I’m trying to do:
elements = response.css("td.s14 > pre::text, td.s14 > pre > a::text, td.s14 > pre > span::text").extract()
for i in range(0, len(elements)-2):
if ".201" in elements[i]:
match = MatchItem()
match["date"] = elements[i]
match["home_team"] = elements[i+1]
match["away_team"] = elements[i+1]
match["home_goals1"] = elements[i+2]
match["home_goals2"] = elements[i+2]
match["away_goals1"] = elements[i+2]
match["away_goals2"] = elements[i+2]
yield match
The elements variable contains all the text shown in the html table in a list. The loop goes through the elements(date, teams, result) and I start to assign the fields to a match item when I recognize the field is a date by searching “.201” (like 07.12(.201)6 for example)in it. I could use regex to recognize date format but I guess there’s no soccer team in the world containing “.201” in its name. When I find the date I know that the next field contains the teams and the next one is the result.
We can test it in scrapy shell:
scrapy shell http://www.stat-football.com/en/t/eng10.php?c=29
[...]
In [4]: for i in range(0, len(elements)-2):
...: if ".201" in elements[i]:
...: match = {}
...: match["date"] = elements[i]
...: match["home_team"] = elements[i+1]
...: match["away_team"] = elements[i+1]
...: match["home_goals1"] = elements[i+2]
...: match["home_goals2"] = elements[i+2]
...: match["away_goals1"] = elements[i+2]
...: match["away_goals2"] = elements[i+2]
...: print match
Writing the spider Link to heading
We’ve played around with the selectors, figured out what path our scraper will follow. How we will actually fetch data? In this section we’re gonna put all these things together and create a working spider. First create a new python file inside the spiders folder in our scrapy project. This file will contain our spider, let’s call it MatchSpider. This is what the project structure looks like now:
Before writing our spider, we have to create an item. In Task One we figured out all the fields we need so now we just have to paste them into an item class that we define in items.py:
from scrapy import Item, Field
class MatchItem(Item):
country = Field()
league = Field()
date = Field()
home_team = Field()
away_team = Field()
home_goals1 = Field()
home_goals2 = Field()
away_goals1 = Field()
away_goals2 = Field()
As we analyzed earlier, we need to follow links twice before scraping the item. Fortunately, scrapy has got a module that makes it easy to define rules for following URLs. This is CrawlSpider module which we are going to use now. We have to create a class and derive it from CrawlSpider. Also scrapy has two attributes we have to define to be able to run the scraper, name and start_urls:
class MatchSpider(CrawlSpider):
name = 'soccer'
start_urls = ['http://www.stat-football.com/en/']
We will be able to run the scraper later using the defined name above. We also have to define the URL(s) scrapy will request first in start_urls.
In the previous section we figured out all the selectors we need. As our scraper first needs to follow 2 URLs before scraping one item now let’s define two rules how the link following should be done:
rules = (
Rule(LinkExtractor(restrict_css="ul#menuA > li:not(.f11.t0.tar)"), follow=True), # LEVEL 1
Rule(LinkExtractor(restrict_css="td.im34.p0612 > nobr:nth-of-type(4)"), callback="populate_item") # LEVEL 2
)
You can see that I use the previously tested selectors here. LinkExtractor is used to find links inside the css selected piece of html. In the second rule we define a callback function which is now “populate_item”. This is the function we’re going to implement to scrape the actual item. As we previously tested the selectors now we just have to paste them into the scraping function. Now we are supposed to populate one item at a time. First assign the fields that are not in the main table on the page. League and country:
league = response.css("h1.f6.nw::text").extract_first()
country = response.css("td.im34.p0612.t0.vat > a > strong::text").extract_first()
Again, we use now the previously tested selectors so we are sure it’s gonna work. Finally, use the loop to iterate over the table elements and scrape most of the fields:
elements = response.css("td.s14 > pre::text, td.s14 > pre > a::text, td.s14 > pre > span::text").extract()
for i in range(0, len(elements)-2):
if ".201" in elements[i]:
match = MatchItem()
match["league"] = league
match["country"] = country
match["date"] = elements[i]
match["home_team"] = elements[i+1]
match["away_team"] = elements[i+1]
match["home_goals1"] = elements[i+2]
match["home_goals2"] = elements[i+2]
match["away_goals1"] = elements[i+2]
match["away_goals2"] = elements[i+2]
The last step we should take is to make this function return (or yield) an item. As we want each match to be a separated item we yield an item at the end of the loop. The whole populate_item function:
def populate_item(self, response):
league = response.css("h1.f6.nw::text").extract_first()
country = response.css("td.im34.p0612.t0.vat > a > strong::text").extract_first()
elements = response.css("td.s14 > pre::text, td.s14 > pre > a::text, td.s14 > pre > span::text").extract()
for i in range(0, len(elements)-2):
if ".201 in elements[i]:
match = MatchItem()
match["league"] = league
match["country"] = country
match["date"] = elements[i]
match["home_team"] = elements[i+1]
match["away_team"] = elements[i+1]
match["home_goals1"] = elements[i+2]
match["home_goals2"] = elements[i+2]
match["away_goals1"] = elements[i+2]
match["away_goals2"] = elements[i+2]
yield match
We run the scraper with this command:
scrapy crawl soccer
Output:
2017-07-14 13:44:26 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.stat-football.com/en/t/rus33.php?c=29>
{'away_goals1': u' 3:1 (1:0)n',
'away_goals2': u' 3:1 (1:0)n',
'away_team': u'Afips u2014 Druzhba ',
'country': u'Russia',
'date': u' 3:3 (1:1)n25 29.04.2017 ',
'home_goals1': u' 3:1 (1:0)n',
'home_goals2': u' 3:1 (1:0)n',
'home_team': u'Afips u2014 Druzhba ',
'league': u'2016u20132017 Russian 2nd Division South (D3-3)'}
2017-07-14 13:44:26 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.stat-football.com/en/t/rus33.php?c=29>
{'away_goals1': u' 2:1 (2:0)n',
'away_goals2': u' 2:1 (2:0)n',
'away_team': u'Chernomorets u2014 Sochi ',
'country': u'Russia',
'date': u' 30.04.2017 ',
'home_goals1': u' 2:1 (2:0)n',
'home_goals2': u' 2:1 (2:0)n',
'home_team': u'Chernomorets u2014 Sochi ',
'league': u'2016u20132017 Russian 2nd Division South (D3-3)'}
2017-07-14 13:44:26 [scrapy.core.scraper] DEBUG: Scraped from <200 http://www.stat-football.com/en/t/rus33.php?c=29>
{'away_goals1': u' 0:0 (0:0)n',
'away_goals2': u' 0:0 (0:0)n',
'away_team': u'Dinamo u2014 Legion ',
'country': u'Russia',
'date': u'25 30.04.2017 ',
'home_goals1': u' 0:0 (0:0)n',
'home_goals2': u' 0:0 (0:0)n',
'home_team': u'Dinamo u2014 Legion ',
'league': u'2016u20132017 Russian 2nd Division South (D3-3)'}
[...]
We are halfway done. Though we’ve got plenty work to do in the next step: processing data. The html we scraped data from was really messed up so we couldn’t fetch data fields separately. We need to separate them in the pipelines.
Process data Link to heading
Okay so now we’re gonna clean each field. We need to implement a cleaning scrapy pipeline. Go to pipeline.py and create a class called CleaningPipeline:
class CleaningPipeline(object):
def process_item(self, item, spider):
return item
In every scrapy pipeline we can use the item and spider objects. A pipeline has to have a function process_item which returns the modified item. Now we’re gonna clean each field of the item, except country, then return it. To make it clear and simple let’s create a separate cleaning function for each field that we wanna modify:
def process_item(self, item, spider):
item["league"] = self.clean_league(item)
item["date"] = self.clean_date(item)
item["home_team"] = self.clean_home_team(item)
item["away_team"] = self.clean_away_team(item)
item["home_goals1"] = self.clean_home_goals1(item)
item["home_goals2"] = self.clean_home_goals2(item)
item["away_goals1"] = self.clean_away_goals1(item)
item["away_goals2"] = self.clean_away_goals2(item)
return item
To make it simple I usually use IPython to quickly test the cleaning functions I’m about to add. I’m gonna go through each field that needs to be cleaned and copy an example scraped, uncleaned value then paste it into IPython and play around with text cleaning functions. Let’s see an example of a typical scraped item:
{'away_goals1': ' 1:0 (0:0)n',
'away_goals2': ' 1:0 (0:0)n',
'away_team': 'Wycombe - Cambridge ',
'country': 'England',
'date': '46 06.05.2017 ',
'home_goals1': ' 1:0 (0:0)n',
'home_goals2': ' 1:0 (0:0)n',
'home_team': 'Wycombe - Cambridge ',
'league': '2016-2017 English League Two (D4)'}
Obviously, we need to do some cleaning to be able to store data correctly. Start with the league field. Example of an uncleaned league field value:
'2016-2017 English League Two (D4)'
We only want it to be “English League Two”. We need to remove the years at the beginning and the part after the first parenthesis. Remember I use IPython:
In [15]: value = '2016-2017 English League Two (D4)'
In [16]: value = value[9:value.index("(")].strip()
In [17]: print value
English League Two
We skipped everything before the first space(years) then stopped before reaching the first parenthesis(“(”). Finally removed all unnecessary spaces at the beginning and at the end with strip(). Now jump back into our IDE and add the implementation of clean_league().
def clean_league(self, item):
value = item[“league”]
return value[value.index(" "):value.index("(")].strip()
value is the uncleaned data (in this case item[“league”]) that we’re gonna pass in process_item function to the cleaning function.
Next one, date field. This is how this field looks like:
'43 17.04.2017 '
In each case there’s a number before the date that we have to remove. Also bunch of unnecessary spaces. Fortunately the date format is consistent so we can do something like this:
In [24]: value = '43 17.04.2017 '
In [25]: value = value[value.index(".")-2:].strip()
In [26]: print value
17.04.2017
We find the first dot(.) and step only two characters back to have the full date and remove the unnecessary number at the beginning. Also removing spaces from the end using strip(). In the pipeline implementation we also need to parse the string as a date then change the format so we can seamlessly insert it into our MySQL database.
Cleaning function:
def clean_date(self, item):
value = item[“date”]
date_str = value[value.index(".") - 2:].strip()
date = datetime.strptime(date_str, "%d.%m.%Y")
return date.strftime("%Y-%m-%d")
Moving on, the next field is home_team. This field should contain only the name of the home team. Right now it contains both teams’ names in a messy way:
'Morecambe - Colchester '
Home team is always the first one. We could do something just like this:
In [30]: value = 'Morecambe - Colchester '
In [31]: value = value[:value.index("-")].strip()
In [32]: print value
Morecambe
Finding the index of “-” selecting everything before that and removing unnecessary spaces.
Cleaning function:
def clean_home_team(self, item):
value = item[“home_team”]
return value[:value.index(u"—")].strip()
With away_team we’re gonna do essentially the same thing but now select the part after the “—” character:
In [36]: value = 'Morecambe - Colchester '
In [37]: value = value[value.index("-") + 1:].strip()
In [38]: print value
Colchester
Cleaning function:
def clean_away_team(self, item):
value = item[“away_team”]
return value[value.index(u"—") + 1:].strip()
Next field, home_goals1 this field is intended to store how many goals were scored in the first half of the match by the home team only.
' 0:2 (0:1)n'
The result inside the parentheses indicates the result of the first half. And now we need the first number before the colon(:). So first remove all the characters that are not inside the parentheses. Try this in IPython:
In [1]: value = ' 0:2 (0:1)n'
In [2]: value = value[value.index("(")+1:value.index(")")]
In [3]: print value
0:1
This piece of code selects only the characters between the parentheses. Now process it further and remove the characters that are after the colon:
In [4]: value = value[:value.index(":")]
In [5]: print value
0
And that’s it now we only have to convert the string to an int:
In [6]: value = int(value)
Cleaning function:
def clean_home_goals1(self, item):
value = item[“home_goals1”]
goals = value[value.index("(") + 1:value.index(")")]
return int(goals[:goals.index(":")])
We’re gonna do the same with away_goals1 that contains the same kind of data about the away team so now we selects the part after the colon inside the parenthesis:
In [1]: value = ' 0:2 (0:1)n'
In [2]: value = value[value.index("(")+1:value.index(")")]
In [3]: print value
0:1
In [4]: value = int(value[value.index(":")+1:])
In [5]: print value
1
Cleaning function:
def clean_away_goals1(self, item):
value = item[“away_goals1”]
goals = value[value.index("(")+1:value.index(")")]
return int(goals[goals.index(":")+1:])
One of the two remaining fields is home_goals2. It contains how many goals the home team scored in the second half. To get this we need to calculate it from the match result and the first half goals. We’re gonna use here the previously cleaned home_goals1 field. But first get the match result from a field value like this:
' 6:1 (2:0)n'
We should be okay selecting the part before the first parenthesis and removing the spaces and converting to integer only the home goals:
In [52]: value = ' 6:1 (2:0)n'
In [53]: result = value[:value.index("(")]
In [54]: home_goals_full = int(result[:result.index(":")].strip())
home_goals_full contains the number of goals scored by the home team in the whole match. We’re gonna subtract home_goals1 from home_goals_full to get the second half goals of the home team. Cleaning function:
def clean_home_goals2(self, item):
home_goals1 = item[“home_goals1”]
value = item[“home_goals2”]
result = value[:value.index("(")]
home_goals_full = int(result[:result.index(":")].strip())
return home_goals_full-home_goals1
The last field to clean: away_goals2. We have to do it similarly to home_goals2. Though now we’re going to calculate with the away goals thus select the number after colon(:).
In [70]: value = ' 6:1 (2:0)n'
In [71]: result = value[:value.index("(")]
In [72]: away_goals_full = int(result[result.index(":")+1:].strip())
Cleaning function:
def clean_away_goals2(self, item):
value = item[“away_goals2”]
away_goals1 = item[“away_goals1”]
result = value[:value.index("(")]
away_goals_full = int(result[result.index(":")+1:].strip())
return away_goals_full - away_goals1
Now we’ve created all the cleaning functions we need. Let’s try to run our scraper but before that we have to enable our CleaningPipeline in settings.py to make it work:
ITEM_PIPELINES = {
'soccer.pipelines.CleaningPipeline': 300,
}
Run the scraper:
scrapy crawl soccer
After running it scrapy shows that there are some errors:
'item_scraped_count': 17407,
'log_count/DEBUG': 17537,
'log_count/ERROR': 120,
'log_count/INFO': 7,
We got 120 errors. Which is not cool. After a little bit of investigation I figured that these caused the errors:
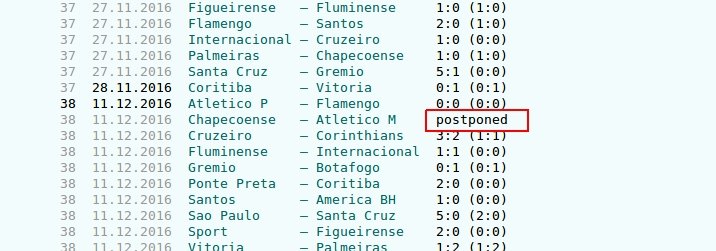
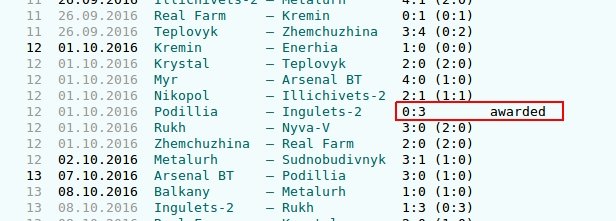
These are some cases we didn’t expect yet. Like matches that were postponed, annulled or awarded to one of the teams without playing the real match. We definitely have to drop these items to not store information about them. Also there are some matches that don’t have result at all for some reason. We should add this piece of code at the beginning of our process_item function. This way none of the pipelines will be executed unnecessarily and the item will be dropped if needed.
def process_item(self, item, spider):
if ("postponed" in item["home_goals1"]) or "awarded" in item["home_goals1"] or "annulled" in item["home_goals1"]:
raise DropItem("Match was postponed, awarded or annulled...")
elif ":" not in item["home_goals1"]:
raise DropItem("No data available")
else:
item["league"] = self.clean_league(item)
item["date"] = self.clean_date(item)
item["home_team"] = self.clean_home_team(item)
item["away_team"] = self.clean_away_team(item)
item["home_goals1"] = self.clean_home_goals1(item)
item["home_goals2"] = self.clean_home_goals2(item)
item["away_goals1"] = self.clean_away_goals1(item)
item["away_goals2"] = self.clean_away_goals2(item)
return item
Now running the spider again it throws no errors.
'item_dropped_count': 120,
'item_dropped_reasons_count/DropItem': 120,
'item_scraped_count': 17407,
We’ve scraped 17407 items (or records). We had to drop 120 items because of the reasons mentioned above.
Database pipeline Link to heading
As our scraper works and cleans data properly, let’s create a pipeline that stores all the data into a MySQL database. First, create a new class in pipelines.py under CleaningPipeline called DatabasePipeline with the usual process_item function:
class DatabasePipeline(object):
def process_item(self, item, spider):
return item
Also, we have to install MySQLdb for python with this command if it isn’t already installed:
sudo pip install MySQL-python
So first of all, we have to initiate a MySQL connection. Create a dictionary in settings.py containing the database settings:
DB_SETTINGS = {
'db': 'soccer_db',
'user': 'soccer_user',
'passwd': 'soccer_pass',
'host': '0.0.0.0',
}
Then we can invoke these custom settings in the DatabasePipeline using from_crawler constructor.
def from_crawler(cls, crawler):
db_settings = crawler.settings.getdict("DB_SETTINGS")
if not db_settings:
raise NotConfigured
db = db_settings['db']
user = db_settings['user']
passwd = db_settings['passwd']
host = db_settings['host']
return cls(db, user, passwd, host)
Now, we have to initiate the MySQL connection inside init constructor using the passed parameters.
def __init__(self, db, user, passwd, host):
self.conn = MySQLdb.connect(db=db,
user=user,
passwd=passwd,
host=host,
charset='utf8',
use_unicode=True)
self.cursor = self.conn.cursor()
Next, in the process_item function we have to create an sql query string that inserts the proper data which will be then executed on the MySQL db:
def process_item(self, item, spider):
query = ("INSERT INTO matches (league, country, played, home_team, away_team, home_goals1, "
"home_goals2, away_goals1, away_goals2)"
"VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s)")
self.cursor.execute(query, (item["league"],
item["country"],
item["date"],
item["home_team"],
item["away_team"],
item["home_goals1"],
item["home_goals2"],
item["away_goals1"],
item["away_goals2"],
)
)
self.conn.commit()
return item
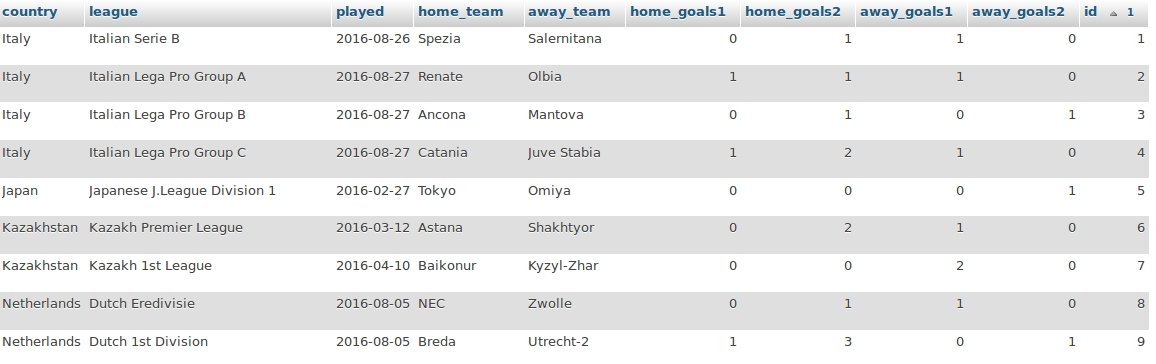
If we’ve done everything correctly we should see about 17407 records in the database in a well-formated way.
Scrapy Cloud Link to heading
If you don’t know Scrapy cloud, it’s a platform that you can use to deploy scrapy spiders in the cloud quickly. For free!
Now we will setup our project on Scrapy Cloud. So in the future we’ll be able to schedule and run our spider from the cloud whenever we want to. First of all we have to register to scrapy cloud here. Then create a new scrapy project:
Deploying the spider Link to heading
Next step is to deploy our scrapy spider. Install scrapinghub command line tool shub:
pip install shub
After you’re done, cd into your scrapy project folder and run this:
shub deploy
The first time you deploy you will be asked to provide your API key and project ID. You can find all these by clicking on Code & Deploys on the sidebar of your scrapinghub project page.
That’s it. On Job Dashboard we can run our scraper and see the scraped items right away.
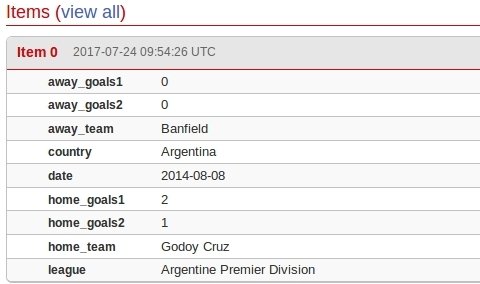
Accessing the data Link to heading
We’ve just setup our spider in the cloud. But how do I access the scraped data directly? Scrapinghub provides a convenient API so you can reach your data in csv or json for example:
https://storage.scrapinghub.com/items/project_id?apikey=your_api_key&format=json
You have to insert your project_id and api key.
Or if you want to make the dataset publicly available without much further work you can just publish it on the Scrapinghub’s datasets catalog. Selecting a finished job and clicking Items page you can easily publish your dataset so it’s available for everyone to download.
You can see what the end result looks like, as I’ve published our soccer project’s dataset here. You can see all the data in your browser or download it in JSON format.
Analyze data Link to heading
Finally, here comes the fun part: querying database to generate insightful reports and stats. Let’s recall what reports we wanna create:
- Average amount of goals per match per league
- Average amount of 1st half/2nd half goals per match per league
- Amount of home wins/away wins/draws per league
- The biggest goal difference between two teams
- The biggest comeback in the 2nd half
- Distribution of average goals per match per league along the season
- Average amount of goals per match per country (if multiple leagues available)
Before we get into this we need to install some libs we’re gonna use to deal with data and to help us create reports. First install install pandas to handle data tables:
sudo pip install pandas
Install matplotlib to generate actual reports:
sudo pip install matplotlib
Average amount of goals Link to heading
Okay so the first topic we step into is the average amount of goals of these seventeen thousand matches. We’re going to create a table which contains the country, league, average goals per match, average 1st and 2nd half goals.
def avg_goals_league(self):
# querying country, league, average number of goals by both teams, 1st and 2nd half average goals
query = ("SELECT country, league, ROUND(AVG(home_goals1+home_goals2+away_goals1+away_goals2), 2) AS avg_goals, "
"ROUND(AVG(home_goals1+away_goals1), 2) AS avg_1st_half_goals, ROUND(AVG(home_goals2+away_goals2), 2) "
"AS avg_2nd_half_goals FROM matches GROUP BY league ORDER BY `avg_goals` DESC")
# reading into pandas dataframe
df = pd.read_sql(query, self.conn)
df.index += 1
return df
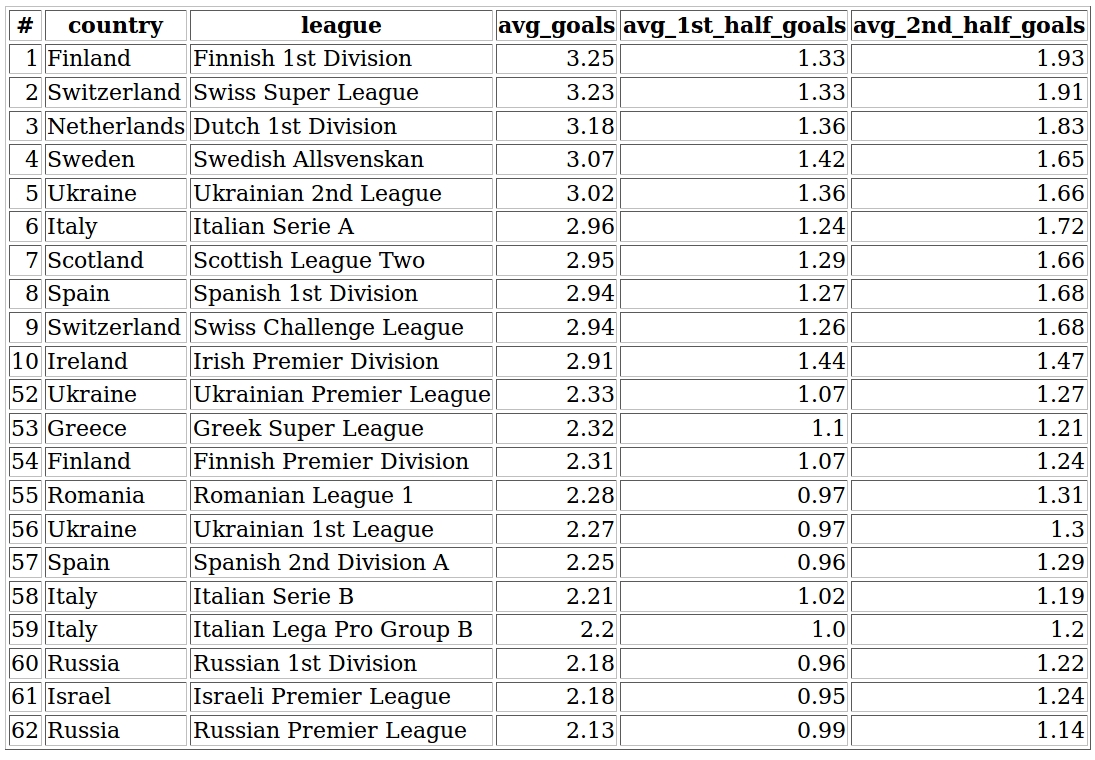
I have never watched Finnish soccer but it looks like I should because they score a ton of goals. They score the most goals per match in the world (at least according to my database which contains 62 European and American league 2016-2017 season matches but of course there are some minor leagues this project doesn’t cover). The Swiss Super League is closely on the second place and a Dutch league on the third place which is not surprising for me. On the last three positions we can see two Russian leagues and the Israeli Premier League they hardly score 2 goals per match. From this table it looks like teams are more active in the second half regarding goals.
Main European soccer leagues Link to heading
Now let’s have a look at the major European soccer leagues only. What about their 1st/2nd half goal scoring? We’re gonna query the db to generate a stacked report about how many goals they score and when.
def main_leagues(self):
# querying league, goals, 1st half goals, 2nd half goals, inlcuding only main leagues
query = ("SELECT league, SUM(home_goals1+home_goals2+away_goals1+away_goals2) AS goals, "
"SUM(away_goals1+home_goals1) AS 1st_half_goals, SUM(away_goals2+home_goals2) AS 2nd_half_goals "
"FROM matches GROUP BY league HAVING league IN ('English Premier League', 'Italian Serie A', "
"'German Bundesliga', 'Spanish 1st Division', 'French League 1')")
# reading data into a pandas dataframe
df = pd.read_sql(query, self.conn)
# creating the plots
f, ax1 = plt.subplots(1, figsize=(10, 5))
bar_width = 0.5
bar_l = [i + 1 for i in range(len(df["1st_half_goals"]))]
tick_pos = [i + (bar_width / 2) for i in bar_l]
# 2nd_half_goals bar
ax1.bar(bar_l,
df["2nd_half_goals"],
width=bar_width,
label='2nd half',
color='#10cc87',
)
# 1st_half_goals bar
ax1.bar(bar_l,
df['1st_half_goals'],
width=bar_width,
bottom=df['2nd_half_goals'],
label='1st half',
color='#31beed')
plt.xticks(tick_pos, df["league"])
plt.title("Main European soccer leagues goals in 1st/2nd half")
ax1.set_ylabel("Scored Goals")
ax1.set_xlabel("League")
plt.legend(loc='upper left')
plt.xlim([min(tick_pos) - bar_width, max(tick_pos) + bar_width])
plt.show()
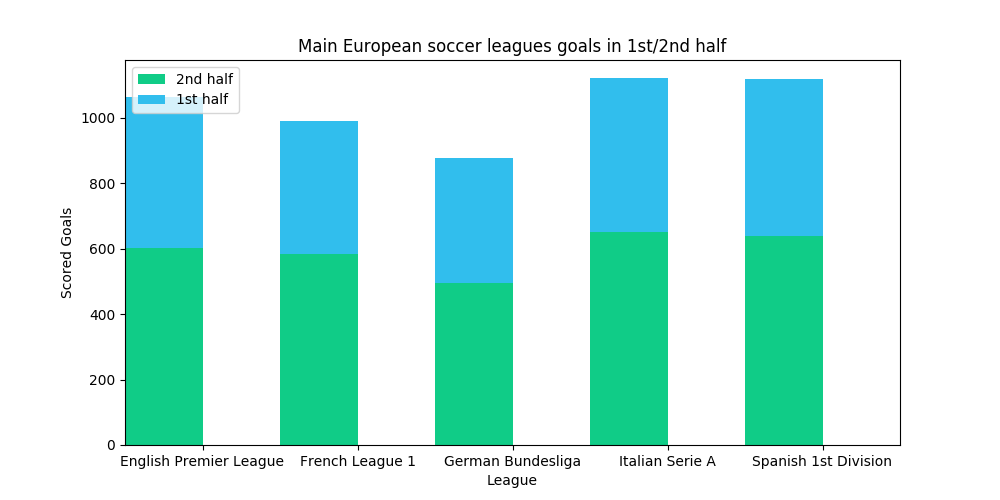
All the leagues have about a thousand goals in the season. The German Bundesliga is the only slightly under it. This diagram shows that, as the previous table shows too, teams tend to score a little more goals in the 2nd half of the match.
Average goals per country Link to heading
Moving on, talk about countries because in our freshly collected data we’ve got several leagues from the same country. Let’s see which country scores the most goals on their league matches. We’re gonna do a similar query that we did for the first report but now we’re grouping by country and not league.
def avg_goals_country(self):
query = ("SELECT country, ROUND(AVG(home_goals1+home_goals2+away_goals1+away_goals2), 2) AS avg_goals, "
"ROUND(AVG(home_goals1+away_goals1), 2) AS avg_1st_half_goals, ROUND(AVG(home_goals2+away_goals2), 2) "
"AS avg_2nd_half_goals FROM matches GROUP BY country ORDER BY `avg_goals` DESC")
df = pd.read_sql(query, self.conn)
df.index += 1
return df
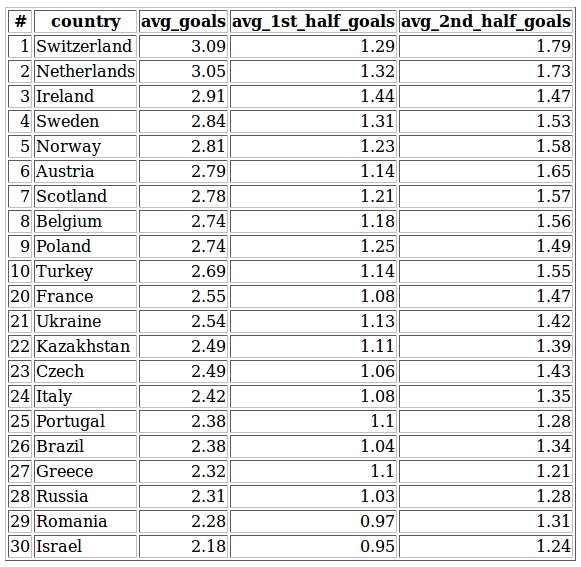
As we previously saw the Finnish league at the top, contrary now we see Switzerland on the first place with 3.09 goals per match. Which is impressive as well. Also it’s interesting to see that while most of the country’s got significantly more goals in the second half than in the first one, in Ireland it’s practically the same amount. Israel is the last one, not surprising considering our first report about leagues. Apparently, they go for the win and not goals.
Distribution of goals Link to heading
Next, it would be great to see a distribution report about goals. We are probably going to see a huge elevation on the diagram near two and three goals. Let’s see!
def goals_dist(self):
# querying the amount of goals for each match
query = "SELECT (home_goals1+home_goals2+away_goals1+away_goals2) AS goals FROM matches"
df = pd.read_sql(query, self.conn)
# creating distribution plots
fig, ax1 = plt.subplots()
ax1.hist(df["goals"], bins=15, range=(0, 14))
ax1.set_title('Distribution of scored goals')
ax1.set_xlabel('Goals')
ax1.set_ylabel('Matches')
plt.show()
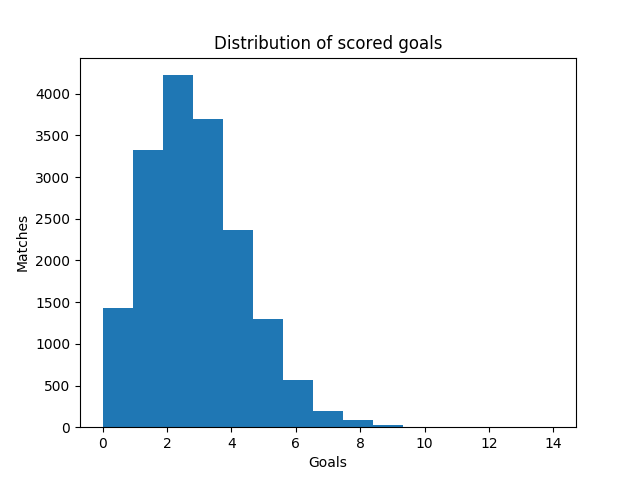
There were more than 4000 matches the last season when the teams scored 2 goals. There were slightly more than 3500 when they scored 3 times. And almost 3500 matches when they scored only one goal. These values have the most density. The fourth one which relatively often occurs is 4 goals per match it happened on about 2300 matches.
Season finish Link to heading
I wanna show you one more report about goals. It should be interesting to see how teams perform as the season is reaching to the end.
def monthly_goals_avg(self):
# querying the year and month and the average goals in the main season, then grouping by month
query = ("SELECT DATE_FORMAT(played, '%Y-%m') AS date, AVG(home_goals1+home_goals2+away_goals1+away_goals2) "
"AS avg_goals "
"FROM matches WHERE played >= '2016-09-01' AND played <= '2017-05-31' GROUP BY MONTH(played) ")
# reading into df
df = pd.read_sql(query, self.conn)
# sort records by match date
df = df.sort_values("date")
# parsing date format
x = [datetime.strptime(d, '%Y-%m').date() for d in df["date"]]
plt.title("Scored goals on average in the main soccer season")
plt.plot(x, df["avg_goals"])
plt.ylabel('Goals')
plt.xlabel("Date")
plt.show()
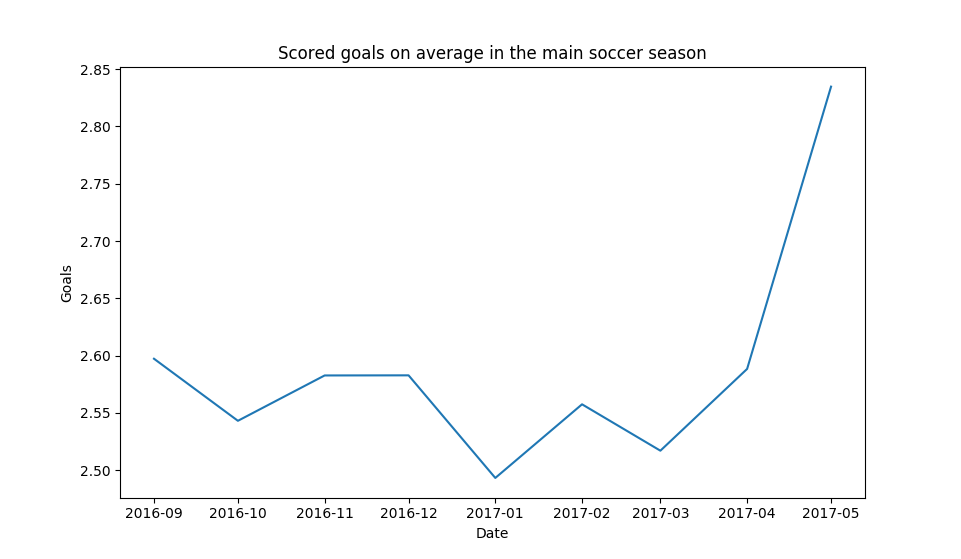
It looks like near Christmas and january teams soften down a little and score the least amount of goals in the season. But later as the season is ending in may they do whatever it takes and score the most goals in this period of time. If you get only one thing from this report, you should rather bet on over 2.5 goals in may than in january for sure.
Biggest blowouts Link to heading
In soccer there are matchups when we’re ready for a blowout and sometimes it’s out of nowhere. Let’s see the biggest differences between two teams the last season regarding goals.
def biggest_diff(self):
query = ("SELECT league, played, home_team, away_team, home_goals1+home_goals2 AS home_goals, "
" away_goals1+away_goals2 AS away_goals, ABS((home_goals1+home_goals2) - (away_goals1+away_goals2)) "
"AS diff FROM matches ORDER BY diff DESC LIMIT 5 ")
df = pd.read_sql(query, self.conn)
df.index += 1
return df

Somewhere in Ukraine two teams played and I don’t know how it happened but one team scored 13 goals the other team only one. Wow. On the second place I see another matchup from the same league goal difference is eight. I should really check out this league. The third one is from Germany a 8-0 blowout by Bayern Munich I guess.
Comebacks Link to heading
In the next report, we’re going to see some comebacks. When a team was down by multiple goals at the end of the 1st half then they managed to finish on top.
def biggest_comeback(self):
query = ("SELECT league, played, home_team, away_team, home_goals1, away_goals1, "
" home_goals2, away_goals2, ABS(home_goals1-away_goals1) AS diff "
"FROM matches WHERE (home_goals1 > away_goals1 AND "
"home_goals1+home_goals2 < away_goals2) OR (home_goals1 < away_goals1 AND "
"home_goals2 > away_goals1+away_goals2) ORDER BY diff DESC LIMIT 5")
df = pd.read_sql(query, self.conn)
df.index += 1
return df

Well, it’s sort of bad that we cannot see here unbelievable comebacks like winning after getting 5 goals in the first half and such. Never mind data is not always surprising. The biggest comeback several teams have been able to make, apparently, is to get up the floor from a 2 goal deficit. If you think about it being behind the other team by two goals and eventually winning the match is actually an amazing performance.
Home Advantage Link to heading
Honestly, soccer is really not about goals. It’s about winning. If a team wins they don’t really care how many goals they had. So as a final report let’s see how often did a team win the matchup when they were at home or away.
def results_pie(self):
# counting home/away wins and loses
query = ("SELECT SUM(home=1) AS home, SUM(away=1) AS away, SUM(draw=1) AS draw "
"FROM (SELECT IF (home_goals1+home_goals2 > away_goals1+away_goals2, 1, 0) AS home, "
"IF (home_goals1+home_goals2 < away_goals1+away_goals2, 1, 0) AS away, "
"IF (home_goals1+home_goals2 = away_goals1+away_goals2, 1, 0) AS draw FROM matches) s")
self.cursor.execute(query)
# fetching only one row because there's no more
results = self.cursor.fetchone()
labels = "Home wins", "Away wins", "Draw"
sizes = [results[0], results[1], results[2]]
fig1, ax1 = plt.subplots()
ax1.pie(sizes, labels=labels, autopct='%1.1f%%',
shadow=True, startangle=90)
ax1.axis('equal') # Equal aspect ratio ensures that pie is drawn as a circle.
plt.title("Match results")
plt.show()
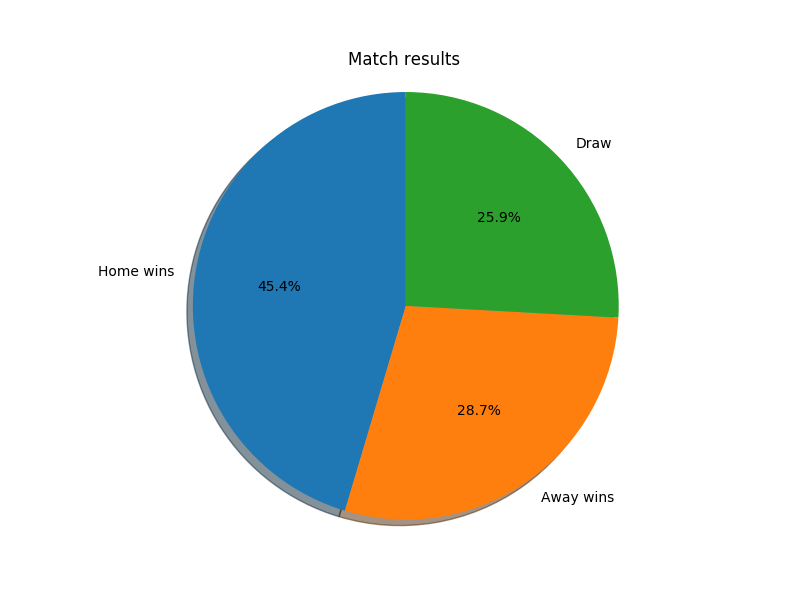
So the teams that played at home won the match almost half the times. Also the amount of draws and away wins are almost the same which is pretty interesting. From this perspective, it looks like the home teams have an enormous advantage over the other team. Actually it’s sort of obvious.
Wrapping Up Link to heading
This is the process one can take to find meaning in web data. First, figure out what data points you really need exactly. Try to think of the end result and reverse engineer the data you have to have in order to create it. Then, find a website or even multiple sites that have the data you need and make sure that website is okay with scraping it or you’ll be able to deal with the consequences. Second, write spiders that pulls your data. I showed you an example how you can extract messy data from html. Third, process and clean data. This step is optional but from my experience you almost always have to clean data to meet your needs. Fourth, here we create the “end product”. Create simple yet meaningful analysis. Fifth, draw conclusions. Act upon the facts. Make data-driven decisions.
Thanks for reading!
Links you might want to check out:
- Scraper Source code: https://github.com/zseta/scrapy-soccer
- Open dataset: https://app.scrapinghub.com/datasets/RS3NYdirkoz/data
- Scrapy Cloud (50% off for 6 months discount code: SASOCCER): https://app.scrapinghub.com/account/signup