AJAX stands for Asynchronous JavaScript And XML (nowadays JSON instead). With AJAX websites can send and receive data from the server in the background, without reloading the whole page. This technique became really popular because it makes it easier to load data from the server in a convenient way. In this tutorial I will cover two major usages of AJAX: infinite scrolling and filtering forms(ViewState). Though you may think that you need to run Javascript to be able to scrape data which was retrieved using AJAX, I’m gonna show you how to do it without launching Splash or other Javascript rendering service.
Using Scrapy to simulate AJAX requests Link to heading
One way to get through AJAX is simply launching a headless browser which renders javascript. But now I will teach you a more effective and faster solution: inspect your browser and see what requests are made during submitting a form or triggering a certain event. Try to simulate the same requests as your browser sends. If you can replicate the request(s) correctly you will get the data you need.
How AJAX works Link to heading
So first, In order to simulate the same requests with the same parameters as a normal browser does you need to have a look at how AJAX works roughly:
Submit AJAX form Link to heading
Take this website for example.
You have to choose an author and then a tag before submitting the form. Now let’s open the inspector of your browser(F12) and find network tab. After submitting you’ll see that the user needs to define two of the sent parameters. So it means that you have to pass these two data in your request.
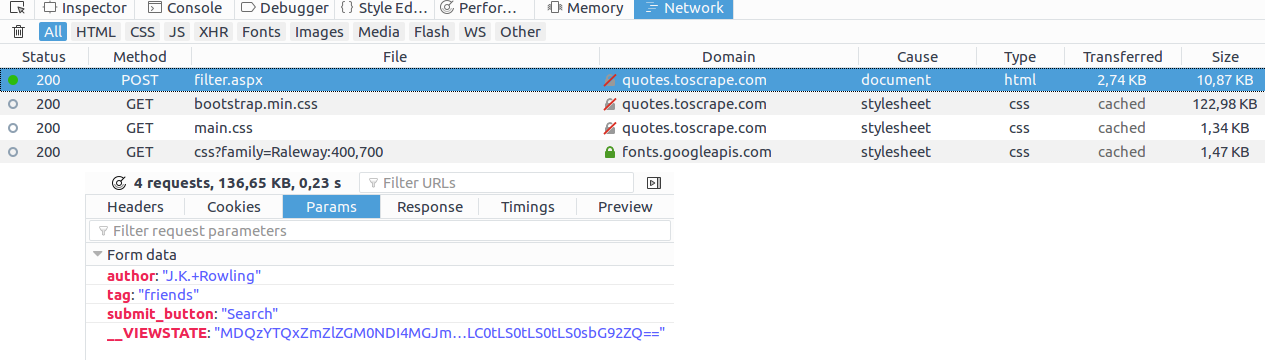
In Scrapy, simply use FormRequest which will take care of sending the parameters:
class AjaxScraper(scrapy.Spider):
name = "ajaxscraper"
start_urls = ["http://quotes.toscrape.com/search.aspx"]
def parse(self, response):
yield scrapy.FormRequest.from_response(response=response,
formdata={'author': 'Steve Martin', 'tag': 'humor'},
callback=self.parse_item)
def parse_item(self, response):
quote = QuoteItem()
quote["author"] = response.css(".author::text").extract_first()
quote["quote"] = response.css(".content::text").extract_first()
yield quote
That’s all you have to do to pass an AJAX form. Figure it out what parameters you should send and use FormRequest in your spider.
Be aware that in the case of the example website above, you have to send one request with both data. Though in the browser you do this in two phases.
Dealing with infinite scrolling pages Link to heading
Infinite scrolling is an alternative to usual pagination. Instead of using previous and next buttons, it is a good way to load a huge amount of content without reloading the page. Fortunately, infinite scrolling is implemented in a way that you don’t need to actually scrape the html of the page. The content is stored on the client side in a structured json or xml file most times. As you scroll, the next portion of content is being loaded.
For example this website uses AJAX to implement infinite scrolling. Inspect the page while scrolling:
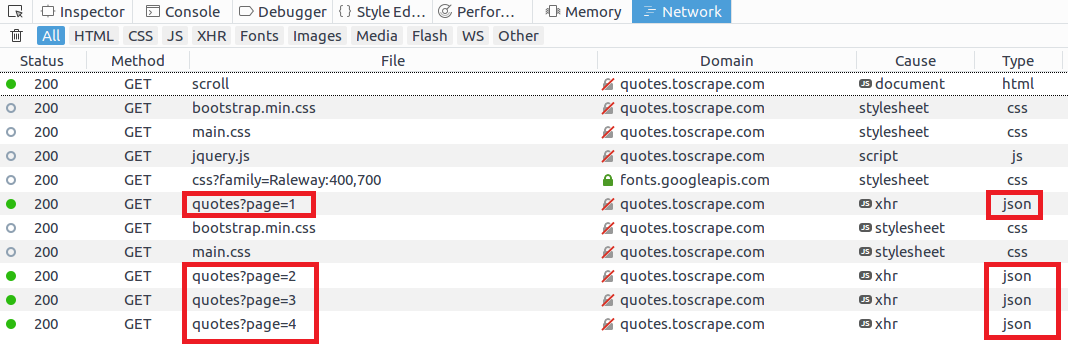
You can see that each URL is based on this template:
http://quotes.toscrape.com/api/quotes?page=1
On each endpoint you find a json file containing the data you’re looking for.
Now you just have to create a spider which iterates over these URLs and extracts items from the json.
class ScrollScraper(Spider):
name = "scrollingscraper"
quote_url = "http://quotes.toscrape.com/api/quotes?page="
start_urls = [quote_url + "1"]
def parse(self, response):
quote_item = QuoteItem()
print response.body
data = json.loads(response.body)
for item in data.get('quotes', []):
quote_item["author"] = item.get('author', {}).get('name')
quote_item['quote'] = item.get('text')
quote_item['tags'] = item.get('tags')
yield quote_item
if data['has_next']:
next_page = data['page'] + 1
yield Request(self.quote_url + str(next_page))