As I talked about it earlier, I’m developing a price intelligence platform for ecommerce companies. If you don’t know, this kind of software heavily relies on web scraped data. The most important benefit of a software like this is the actionable insights you can get out of pure data. That’s why it’s crucial to have a well-organized system which delegates data from start to end.
The data in PriceMind is like blood. It has to flow over and over again in order to properly meet business standards and needs. Near real-time data is a big part of the whole database ecosystem. It constantly keeps the user up-to-date by delivering fresh competitor data. On the other hand, historical data is just as important as current data. It gives the customer a chance to recognize pricing strategies and patterns used by the competitors. So these two types of data are continuously flowing in PriceMind to satisfy users.
Now let’s have a look at the path the data follows on its way to the end user.

Scrapy Cloud Link to heading
I told you about this earlier that I use scrapy cloud and I’m highly satisfied with it yet. I have deployed spiders in scrapy cloud with pipelines that run every day - multiple times. The whole web crawling module is fully automatized so I don’t have to deal with it anymore. It just works. I’m happy with it right now.

Database Link to heading
I use a MySql based database in a cloud server. The data which is inserted into the database is not 100% raw. Because I cannot just fetch data from websites then push it into a db. I need to first clean it up a little and standardize. These tasks are done mostly by scrapy pipelines. Besides, I have to run some small scripts (currently with cron) to be able to maintain a normalized dataset. At this point, the data is clean, standardized, normalized and ready to be queried by the application.
Application backend Link to heading
The backend has two main tasks when it comes to the data flow. One is receiving data. Other one is modifying it for frontend needs. I use flask-sqlalchemy to query the database. Also, I make use of pandas dataframe to help make the transition between backend and frontend. I have developed an abstraction layer for the database called reports.py. This module is responsible for producing data structures that can be passed to and accepted by the frontend. For each chart or diagram on client-side I have a function in reports.py returning the data needed for that chart or diagram. I found that this solution is reasonable and scalable in long-term, also easy to maintain so far.
Application frontend Link to heading
Finally, the last phase of data flowing is the frontend. I use mostly google charts library and this to generate reports. Data transition from backend to frontend is pretty seamless thanks to Jinja2. I usually just pass a dictionary as parameter to the html template. If I have to pass a big chunk of data (eg. table data) I may serialize it to JSON then parse it in Javascript. (Btw, my design skills are still 💩 so not spending much time on that)
Actionable insights Link to heading
This is the final stage. This is where the user decides to take action based on PriceMind reports. The eCommerce world is so saturated that each company is looking for something that gives them a little bit of an advantage. Price Intelligence is something that you need to have if your competitors have it just to keep up with them. If they don’t, then you can use it to get that little bit of advantage over them.
What I’ve been working on lately…
Creating the login system Link to heading
I finished the prototype version of PriceMind without having a registration/login system. But as I’ve been developing and improving it I came to a realization that now I need to create the login system because soon we will have multiple clients hopefully and it’s impossible for them to use the same account.
If you read my previous article you know that I use Flask as the backend programming language. There is a cool extension which helps me to create the login function. Flask-login handles user session management and other common tasks of logging in and out. It”s pretty useful. (Side note: I hope I’m not going to end up reinventing Django, because of the many extensions I keep adding to Flask.)
New feature Link to heading
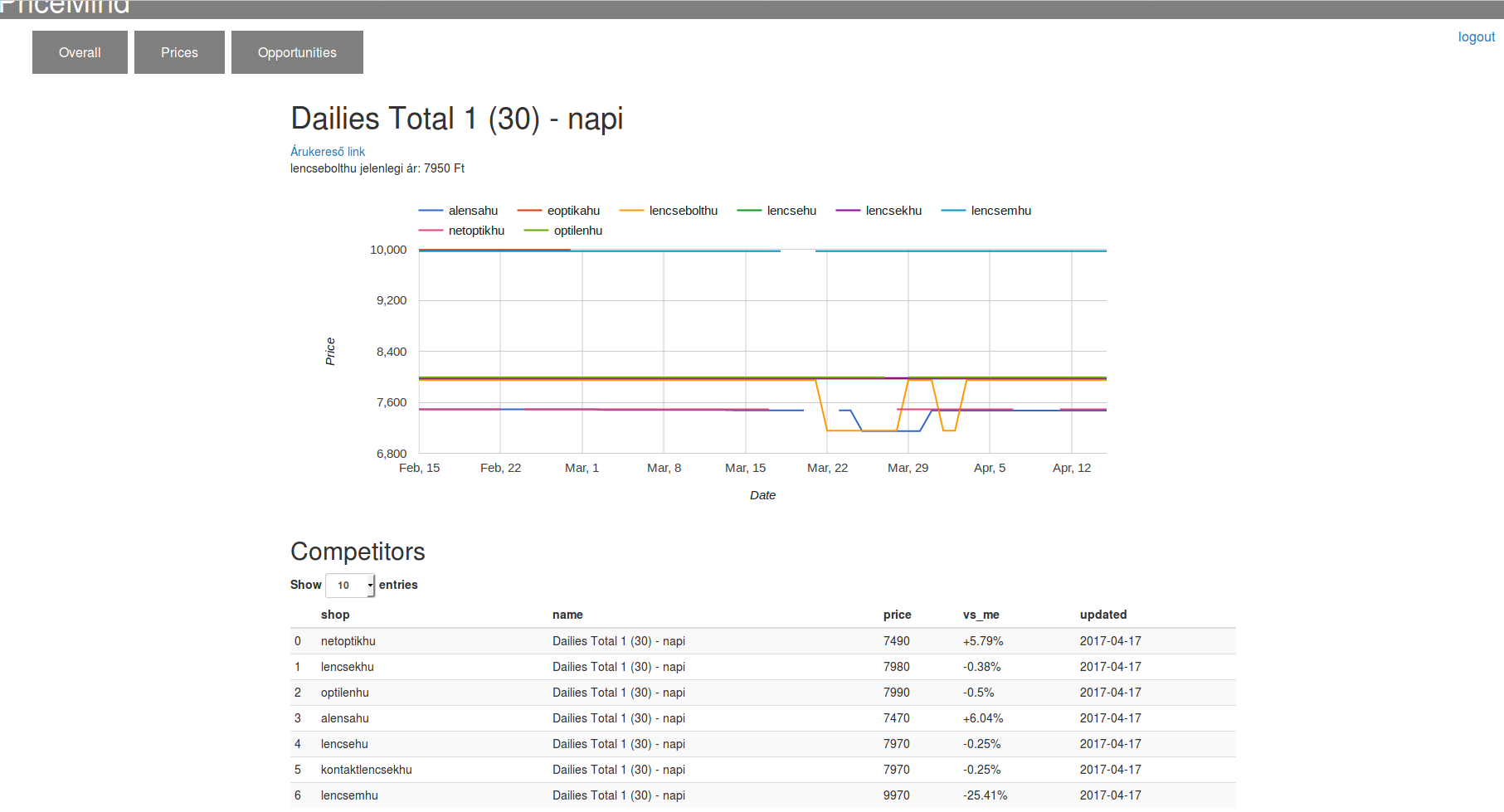
In the last five days I have been spending my time on developing a new feature into PriceMind. This feature is Price History. Now our clients can analyze the recent pricing history of any product. They can see which competitor changed its price of a product and when. With this they can gain insights about the pricing strategy of their competitors. Also, they get a broader idea where they are in the pricing competition at the moment. This is what it looks like:
Setting up workflow with jenkins Link to heading
I guess I didn’t told you guys yet that I use git to manage version control and I have a remote repo on Gitlab.
So what I’ve been trying to achieve lately is to be able to automatically deploy the latest releases of PriceMind to the remote server. Building the project and maybe running some additional scripts or integration tests. I have worked with jenkins in the past so I knew that this is what I need now. Besides, I will definitely need to hire some developers to work on PriceMind in the future so I will need to have some kind of continuous integration system anyways.
So my workflow looks like this at the moment:
- Creating cards to Trello about new tasks
- Local changes(bug fixes, new features) on a local branch
- Push local branch
- Merge with develop branch
- Jenkins pulls new code and builds the project
- If everything’s fine, project is deployed (on a developer server)
Of course, when I won’t be the only who works on the project this workflow will need to be changed slightly.